Debugging Deep Model-based Reinforcement Learning Systems
← HomeI saw an example of this debugging lessons for model-free RL and felt fairly obliged to repeat it for model-based RL (MBRL). Ultimately MBRL is so much younger and less pervasive, so if I want it to keep growing I need to invest that time in all of you.
For an illustrative case-point, consider these two SOTA codebases:
- TD3: Twin Delayed Deep Deterministic policy gradient.
Reading the code:😀. - PETS: Probabilistic Ensembles with Trajectory Sampling.
Reading the code: 🤪.
By the title alone, it sounds like they may be equal in complexity, but for model-free algorithms, the modifications take only a few lines of code. In MBRL it takes building entirely new engineering systems (more-or-less). The PETS code has way more moving parts. This post is set up in the following format:
- Overview of model-based RL,
- Core things to tinker with in these systems,
- Other considerations that may come up (e.g. when working with robotics),
- Practical tips: quick things to change or run for a big potential improvement, and
- Conclusions.
Into the woods we go! This is a brain log of the things I have learned and been stuck on when implementing model-based RL algorithms and applications. To go to the list of practical tips, click here.
Note, want to learn through code? I recommend checking out our MBRL-Lib.MBRL: Overview
Model-based reinforcement learning (MBRL) is an iterative framework for solving tasks in a partially understood environment. There is an agent that repeatedly tries to solve a problem, accumulating state and action data. With that data, the agent creates a structured learning tool — a dynamics model -- to reason about the world. With the dynamics model, the agent decides how to act by predicting into the future. With those actions, the agent collects more data, improves said model, and hopefully improves future actions.
A core framework in a lot of — but certainly not all — recent progress in MBRL is model predictive control (MPC). MPC, which can be optimal, is a control framework for using structured dynamics understanding to solve an optimization when choosing an action. A crucial component of this is the goal of predicting far into the future, and deciding in a receding horizon manner. Though, in MBRL this long-term planning is balanced with the understanding that models diverge exponentially as the prediction horizon grows. Many of the debugging tools I discuss are from the lens of long-term planning for control, and could be tweaked to be better phrased for methods using value functions and model-free control.
This post aims to steer clear of any numerical issues in particular, which are research problems in deep learning of some sort, favoring a discussion of trade-offs and weird portions of the system that tend to cause problems (even if we do not know why)!

My biases
I am certainly biased towards deep MBRL for robotics. In the future I see MBRL, and other types of RL being used in many applications, most of which will be digital. I have little experience with CNNs / computer vision / recurrent models, so my advice is very focused on one-step dynamics models. You can see my publications and more obvious biases in my CV.
Core Tinkering
Any RL system is primarily determined by the motivation of the tinkerer. The core difference between model-based methods and their model-free brethren is the additionof a model. Trying to summarize all the properties of interest for a dynamics model in an iterative, data-driven system is overwhelming, and needed. I see the modeling problem as primarily being a data problem and a modeling problem. The line between these quickly is blurred.
Dynamics Model Parametrization
How you structure (and gather) your data is of crucial importance.
- Model type: the craze is with deep neural networks these days (admittedly the hype is chilling), but there are plenty of other models to consider. Neural network models are becoming easier to use (especially when considering online control) due to the investment in small graphics units, e.g. Jetson’s).
- Linear models (e.g. least squares to a state-space system, something like this) are good for elementary systems. It is not quite the least squares approach, but here is a paper from Professor Levine’s earlier days using a linear model for dynamics.
- Gaussian Processes are good when you don’t plan to plan online, have <8 dimensional state-action space, or like structured uncertainty estimates. The slow planning comes from needing to invert a matrix of the number of training points cubed for prediction. I think that if NNs did not exist, GPs would be by far and ahead the leading candidate (PILCO uses them). GPs in this case are heavily limited by a dataset filtering problem to keep the prediction time fast. I would still consider GPs for offline applications though. Also, a tool like Bayesian Optimization is useful as a companion to a lot of MBRL work (it in itself is a variant of MBRL).
- Recurrent models sound fantastic because the goal is to predict the long term future, but… In my experience, LSTMs are not that well suited because they are also hard to train and tend to require more data than control problems provide (I suspect this opinion may change in the coming years). There are two key examples to where LSTMs have been used in MBRL, one outweighing the other (for now). Dreamer uses an LSTM as a recurrent model for a latent space, and collaborators with Professor Levine applied collocation to a similar latent space. We tried to baselines LSTMs for state-predictions in this paper, but I think we need some more expertises to make it work (if you have the skills for this, reach out!)
- Use the delta-state parametrization: predicting the change in state rather than the true state tends to be better behaved and more useful for control. I have my doubts that it works as well for very unstable (dynamically, think eigenvalues) systems. It is formulated as:

- Model capacity has not been pushed to its limit in most tasks. Most papers use canonical values (2 hidden layers, 256 nodes, 5 models in ensemble) and whenever I tune this I see very little impact. My hunch is that the model capacity tends to be way higher than is needed, so most of model training is fighting overfitting with noisy data.
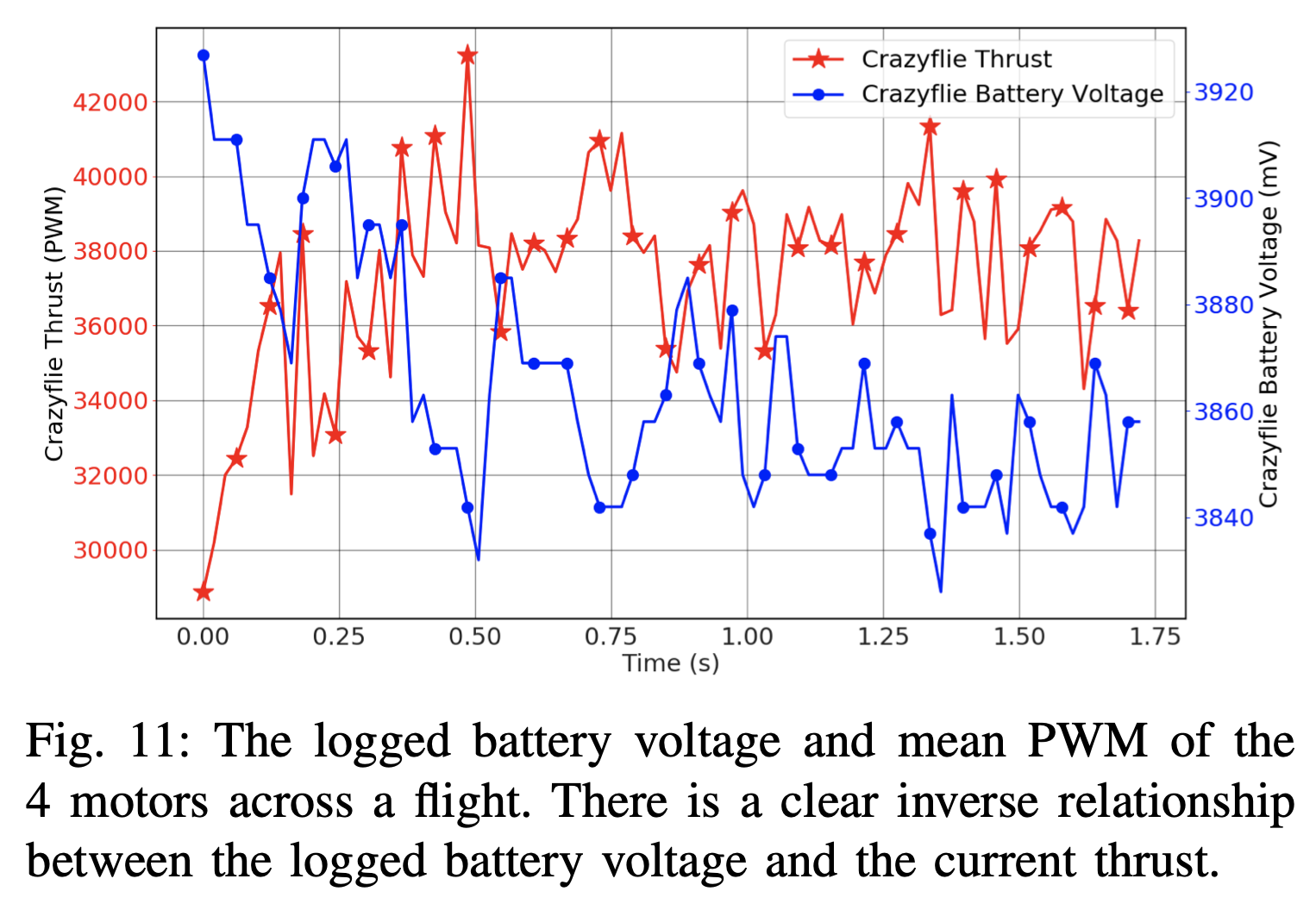
- Advanced model options: append history to model input (if the time-constant of the dynamics is well slower than the control frequency actions may take a couple of steps to engage. Increase the models understanding by appending a few past states and actions), context variables can be passed into the model as an input and not predicted as an output (e.g. battery voltage, but they can be misleading -- in this case, the load of changing the motor voltage varied the measured battery charge by so much that it was not useful in understand dynamics)
{kind=link}
Dynamics Model Supervised Learning
When the core supervised learning of the model is broken, as in error is not converging with our savior Adam, see many tutorials on this at the base level, but otherwise:
- Model initialization can be important. Due to its core use in control, a model that is a bit off can result in performance being stuck at 0. Re-use someone else’s model initialization if you can (it turns out people use clipped normal distributions generally, which is not in PyTorch yet).
- Anger point: Some models use incremental training, some do not. In the PETS paper, the Half Cheetah results that it touts is using a slightly different model training than vanilla re-training after each trial. In this case, the model parameters are not reinitialized, but rather the optimizer takes more gradient steps from the model parameters used in the previous trial. This results in a slower model change, but it is not well theoretically motivated.
- Need state/action preprocessing (e.g. angles to sine and cosine of angle): when planning in systems with angles, if you expect the angles to wrap around (e.g. a heading that keeps turning left will grow from 0 to 2pi to 4pi), the states here need to be processed before labeled to make equivalent angles matched.
Predicting Multiple Steps
Compounding error emerges when planning multiple steps into the future by accumulating small errors as inputs to the dynamics model. The compounded prediction pass is formulated as:

- Common bug: the user does not re-normalize predicted states before passing back into model. Error in this case will blow up really fast. If you want to visualize the trajectories / use them for control (where the whole trajectory matters) prediction usually happens as input -> normalized input -> normalized output -> output -> normalized input …
- Above I mentioned state wrappers for angles, integrating those into predicting trajectories can learn to problems with state/action wrappers. Normally, this is a dimension mismatch in your model (angle becomes sine and cosine of angle), but it can be a pain to implement.
From Modeling to Planning
Planning usually takes the general form of a finite-horizon model predictive controller:

- Predictive horizon too short: some reward functions you won’t even reach without a long enough horizon — when this happens, all candidate actions are equivalent at 0 reward (reduction to random policy)! For example, in a task like manipulation that is completed when an arm gets to a certain epsilon-bubble, with a short model horizon, none of the action sequences may get there.
- Predictive horizon too long: best-case point is MBPO, a fun case is PETS. They have an appendix sweeping over horizon (lightly)
- Planning horizons are also not well understood (DeepMind published an entire paper on this subject)
- Theoretical limitation: There is not a signal connecting the measured reward to the dynamics model or optimizer. This is something we call Objective Mismatch, and designing algorithms to address this could be very impactful.
- Cool option: If using probabilistic models of some sort, you can plot the model uncertainty at each step in the prediction horizon. Traditionally (not sure why theoretically), the variance diverges to large values or collapses to 0 when the model is outside its training set. This can make for interesting dynamic horizon tuning, but is very hard to design.
Control Optimization
Wall clock time is a huge problem. With all of the planning into the future, MBRL algorithms take a lonnnnnnng time to run. For example, re-producing the PETS experiments on Half Cheetah takes 3 days to run on a GPU. An engineer I worked with literally started experiments then went on holiday time to wait for them. There will be incremental progress improving this, but also maybe someone can build on this Jax implementation that is supposed to offer 2-4x time improvements for some RL algorithms?- Experiment carefully: MBRL is not a research area to just throw tons of experiments at due to the above time limits. Keep track of what you are planning and what you are currently running. Use Hydra to manage your experiments.
- Weird consensus: the impression I get from most MBRL researchers using sample-based planning is that the controller works by choosing slightly incorrect actions that over time averages out to a good, but not perfect plan. Understand that current algorithms likely will output weird action sequences if you zoom in on any random seed.
- Art: sample-based MPC working on average means you want a model that is very accurate with the best trajectories you have (expert), but also in the nearby area for robustness.
Tuning Reward Functions
MBRL seems to be a bit more closely tied to optimal control methods, and some of the papers formulate the rewards a little more differently (and when you aren’t using the standard baselines, there is more room to tune them)!
- Practical trend: data distribution (coverage) is proportional to performance. If you have a environment your MBRL task can solve, you can improve related task performance by getting more labelled data there (think moving the goal state from 0degrees to 15degrees), but you can also limit peak performance by including more random transitions in your dataset.
- If you suspect your reward function is weird, consider reparametrizing first, tune second. For example, a cartpole task traditionally gets a living reward for being in a wide range of states (reward is 1 whenever trial is not done), but you can change the behavior to be optimal in the control theory sense by adding a quadratic cost away from the origin.
- Scalar multiple of rewards suck to tune: tuning the weights of attitude and trajectory weights is not easy. I hope hierarchical RL takes some of the weight of this.
- Smooth and bounded rewards over quadratic costs. For example, taking the cosine of an angle is a nice bounded function that gives a higher value around 0. It drops off much more nicely than the negative of the square.
Exploration
Gosh, in MBRL exploration happens at the interface between the model and the planner, which makes designing for it very tricky. I wrote a short post on why this is so weird here. Ultimately, having working MBRL for 3 years now almost full time, exploration is the least-clear path forwards.
To date, exploration seems to happen by chance luck, and integrating more explicit exploration mechanisms into planning (prioritizing an action distribution) could come at the cost of having the wrong model training distribution. I would love to be proven wrong or hear that it is less complicated than I think, of course. A couple of research directions that I feel obliged to share are making improvements on exploration. The first is plan2explore (by the author of Dreamer, Danijar Hafner, reminded to me by Robin Chauhan):
By maximizing latent disagreement, Plan2Explore selects actions that lead to the largest information gain, therefore improving the model as quickly as possible.Information gain is a very reasonable approach for the training phase, and it can be turned off at test time (like entropy-based methods in MFRL). A second paper is Optimistic Policy Search in MBRL. These two are likely only scratching the surface, so please let me know if I missed anything.

Other Considerations
There are plenty of things outside the purview of Deep RL that affect your system. This is what you learn from trying to advance reinforcement learning from the angle of embodied agents. These practical considerations can have anywhere from 0% to complete-app-breaking influence on your project. When people start trying to productize Deep RL, these will be more main stream.
System Properties
Some systems are really not meant to be modeled. Deep RL does not discuss things like system eigenvalues, noise, and update rate enough. Ultimately, take a lesson from popular linear estimators and know that as you go further into the future with no measurements, the lower bound on model error grows hilariously fast.
Sensitivity to Hyperparameters
A recent paper I was lucky enough to contribute to changed my mind of the potential of and sensitivity of MBRL algorithms to the parameters using them. Ultimately, the core idea is that the best parameters for MBRL may change based on the trial number (e.g. as the agent gets more data, the model gets more accurate, so the predictive horizon can be longer). This is on top of the standard deep learning and reinforcement learning parameter sensitivity.
In general, I would say if you are in a well-supported lab, use an automatic machine learning (AutoML) library, but if you are not, work in an environment that is less competitive (e.g. a real robot you have rather than Mujoco). You can learn more here.
Robotics Problems
I am an (potentially inadvisable) unique case where the first time I deployed a MBRL system, it was in the real world. Do not do this, but there are certainly things you can learn about MBRL by using it in the real world that apply in simulation.
- If searching for a stabilizing policy in control, make sure you compare to a random policy. When working on this paper doing attitude control for a quadrotor, we learned a lot about the fluid dynamics of flight. Long story short: when a quadrotor is close to the ground, the updraft from its propulsion bouncing back creates a little pillow where the robot will effectively have more stable poles (the air both keeps it from sitting on the ground, and makes the pitch-roll unstable pole at 0,0 almost passively stable).
- If your reward function is simple, correcting exploitative behavior is not really possible. For example, in the same paper I had the problem (or feature) where the quadrotor realized high thrust was a more stable mode. In this flight mode, it was limited by the height of the room, and progress was saved by me catching the micro-quadrotor as it crashed back towards earth. High-risk, high-fun research got me started here. A more in-depth question is, what part of the model or planner (random sampling in this case!) made it so that behavior only occurred part of the time.
- Preclusion of application via computation problems. Because of the system-nature of MBRL with MPC, actually putting this on robots is really hard. It comes down to decisions like: do you run MPC onboard or send the state via radio / wire to another computer to compute the actions. Running controllers off-board makes synchronization, delay, and dropout (communication, not NNs) even more important.
There are no good deep RL libraries designed around real-world systems to data. In the quadrotor project I flew 10 flights of data, transferred it with an usb drive, transferred it back, and ran more experiments. If you look at the learning curve there, getting it was a full day of data collection, training, and hope. You can therefore infer that it obviously took a long time to get that paper done :). A hope I have is that modern open-source projects start giving thought to how their algorithms could be used on real-robots at scale, or maybe that is more of a startup question (product). - Change your control frequency: If you sample states less frequently, the noise in your measurements becomes less of an influence on your labelled training points, which can help your model accuracy. A lower frequency also translates to planning further into the future in time given a set number of steps. Though, for many applications, pushing the control frequency higher lets the behavior correct for bad actions faster.

Practical Tips
Here is a list of practical tips for various parts of the puzzle.
Dynamics Modelling
- Append history to model input (if the time-constant of the dynamics is well slower than the control frequency actions may take a couple of steps to engage. Increase the models understanding by appending a few past states and actions).
- Context variables can be passed into the model as an input and not predicted as an output (e.g. battery voltage, but they can be misleading -- in this case, the load of changing the motor voltage varied the measured battery charge by so much that it was not useful in understand dynamics).
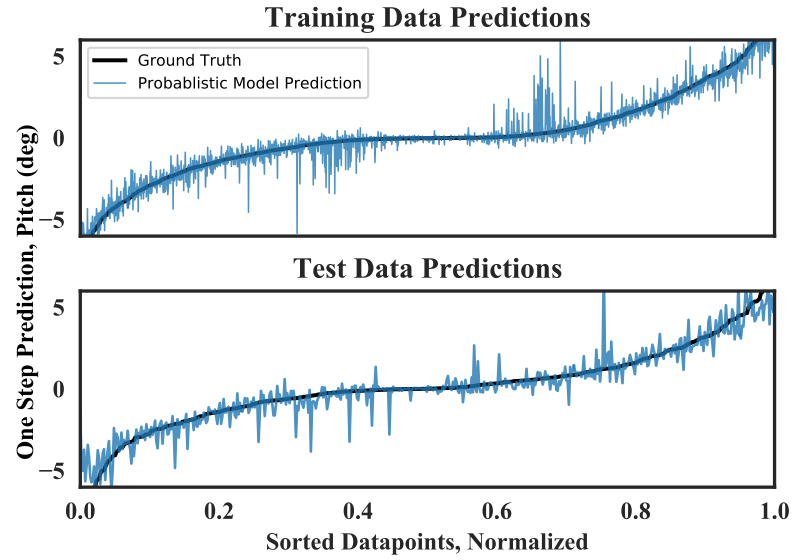
- Look at the sorted one-step predictions in your state-space (Example here). The points at the edge of the system will tend to look like error is higher, but they should not blow up to infinity.
- Visualize many seeds of predictions and median prediction error across multiple horizons. It is likely the case that the bad outliers of prediction may disproportionally harm your performance.
{kind=link}
Control and Planning
- Visualize all of the candidate trajectories in a couple dimensions — they should look very diverse.
- Visualize planned trajectories vs ground truth with different replanning frequencies. This will be a series of slowly diverging plans, and it can regularly show the most challenging part of a trajectory by where the plans diverge.
Looking at how closely the predicted trajectories (with chosen actions) match the eventual trajectory is beautiful and useful for considering if your optimizer seems to do anything useful. A lower re-plan frequency here is really just to lower how cluttered your visualization is. - Check the performance of your agent on the real dynamics (Albert Thomas reminded me of this one). This takes the dynamics modeling question out of the loop temporarily, but can be very hard to implement. This can be tricky to implement because you need to set the state of the simulator to run your optimizer over it many times and most simulators are not parallelized for GPUs (the best implementation I have used spawned CPU children in Python to accelerate). Note that you do not need to sample over as many actions when doing this because the predictions are actually accurate.
- Don’t actively design an exploration mechanism, but visualize how it is working by looking at your dataset over time.
- Something that is not written enough: cost = -reward. You can change any cost function to a reward.
Visualizing MBRL Systems
It is important to visualize what MBRL is doing along some core axes: planning, data accumulation, simulation, and more. Here are some visualizations I have made that helped me learn what is going on.



Code examples
Check back soon for a major open-source MBRL project I have been working on. Otherwise, some lighter-weight simulators I have built. A lot has been built on the original PETS implementation, but it is in the O.G. TensorFlow.
- A core repository I helped support with Facebook AI is now live here. The paper describing its design choices can be found here.
- A good dynamics model can be found here. Why is it useful? It is set up to handle model formulation changes (e.g. true state vs. delta state prediction), normalization, etc. separate to the model type. Also, dynamically making the neural network from a configuration file is needed for any advanced machine learning project.
- A messier repository of many libraries, plotting codes, environments, related optimizers and model simulations, are here (honestly use at your own risk, but browsing for inspiration could be useful).
Conclusions
I am very optimistic about the future of model-based methods. For some level of research-agenda protection, I don't keep the running list of all the things that I want to do open online (I don't have the people to solve all of them!), yet I am very open to working with new people and talking through these challenges.
Ultimately, when you zoom into any piece of the MBRL puzzle, it is pretty clear that each sub-mechanism is relatively suboptimal. Pushing each piece individually has years of research left in it.
I hope that these pieces start to fit together better, we may get a sort of resonant response, where MBRL unlocks all the things people hope for in it:
- Generalization via a better understanding of the data,
- Interpretability by more optimal controllers with accurate models, and
- Performance by all the pieces gathering.
A good way to look at everything I have public on MBRL is to start from my writing index and Google Scholar.
Research Progress
My friend Scott Fujimoto summarizes the state of model-based RL pretty well: it is very intuitive to humans (we plan things out in our head!), but actually trying to implement it is pretty horrendous. I’m hoping to make progress on this.
Some recent papers that you should be aware of in the trajectory of MBRL:
- PILCO (2011): Gradient-based policies through a dynamics model.
- MPPI (2017): An alternate model-predictive control (MPC) architecture.
- PETS (2018) & POPLIN (2019): Sample-based MPC with weaving trajectories together.
- Dreamer (2020) & DreamerV2 (2021): Visual MBRL is getting good!
- MBPO (2019): Model-free RL (SAC) on a learned model.
- Objective Mismatch (2020): We are starting to understand why MBRL is weird (in theory and numerical measurements).
Advice
Work on from someone else's implementation when you can, or branch off from their code. I've been around, and helped with, a couple open-source attempts at MBRL code and the pain points are generally things you would not anticipate. These pain points are compounded when you have to debug both the model and planning side -- do yourself a favor and start with one half that you know works.
The field is young: if you think you're onto something, just try it.
Visualize the plans, and actions from models (something model-free cannot do, take advantage of it)! Because the action plans are so crucial to control, learning to whisper with what looks right and what looks long will help you a lot. Below is an example of two dynamics models with the same average accuracy, but one makes for noisy control (from my paper). I also think that the tools starting to be built in this paper are compelling for MBRL.

Acknowledgements
Thank you to Luis Pineda for many useful discussions on debugging MBRL while building something exciting. Many of the lessons learned here were with Roberto Calandra, and some with Daniel Drew and Omry Yadan. Thank you to Eugene Vinitsky for feedback on my first draft.
If you feel the need, I have made a citation for this one.
@article {lambert2021debugging,Thanks for reading! If you have a question, ping me on Twitter.
author = {Lambert, Nathan},
title = {Debugging Model-based Reinforcement Learning Systems},
year = {2021},
howpublished = {url{http://natolambert.com/writing/debugging-mbrl} },
}