Exploitation Exploration (in MBRL)
← HomeModel-based RL does this wonky thing where it explores by letting its controller think it is being successful (planning is actually wrong), but it gets data in a way that works so there hasn’t been huge changes to it. This paradigm of exploring through error, or in MBRL’s case, exploring through model exploitation, can come up in any system that doesn’t have an active exploration mechanism built in.
Review - Classic Exploration Strategies
To start, let’s recap what is generally referred to as the exploration literature. These are all methods where exploration is and actively designed part of the system. I quote directly from Lilian Weng who has a great article on the active exploration mechanisms.
As a quick recap, let's first go through several classic exploration algorithms that work out pretty well in the multi-armed bandit problem or simple tabular RL. A) Epsilon-greedy: The agent does random exploration occasionally with probability ϵ and takes the optimal action most of the time with probability 1−ϵ. B) Upper confidence bounds: The agent selects the greediest action to maximize the upper confidence bound Q̂ t(a)+Û t(a)Q^t(a)+U^t(a), where Q̂ t(a)Q^t(a) is the average rewards associated with action aa up to time tt and Û t(a)U^t(a) is a function reversely proportional to how many times action aa has been taken. See here for more details. C) Boltzmann exploration: The agent draws actions from a boltzmann distribution (softmax) over the learned Q values, regulated by a temperature parameter ττ. D) Thompson sampling: The agent keeps track of a belief over the probability of optimal actions and samples from this distribution. See here for more details. The following strategies could be used for better exploration in deep RL training when neural networks are used for function approximation: A) Entropy loss term: Add an entropy term H(π(a|s))H(π(a|s)) into the loss function, encouraging the policy to take diverse actions. B) Noise-based Exploration: Add noise into the observation, action or even parameter space (Fortunato, et al. 2017, Plappert, et al. 2017).Two newer exploration strategies are detailed in the blog post:
- Count-based exploration: heuristics to track how frequently you visit a state.
- Prediction-based exploration: heuristics to track how your dynamics model (a tool to predict how the environment evolves) performs, in the sense of prediction error, in different regions of the state space. These turn into sort of error-regularizationprediction mechanisms. They reward systems for new points, but also search for uniformity over model capacity. A version of this happens indirectly in MBRL.
The Exploration Dance in MBRL
Model-based RL is a dance between getting an expressive model (and the vast amounts of data needed to do so) and having a model that your controller design can work with. Contrary to many optimal control methods, the goal is not to get a perfect model, but rather a model that solve your task (or tasks).

The question with trying to modify the current approach is: if I try and make the controller know the model is inaccurate (or something similar), does the system lose all of the random exploration it has?If you change the mechanism for getting the new data, the system may cease to work at all. It’s a chicken-egg problem (all of exploration is, but when you don’t understand the exploration mechanism it is a chicken-egg-knife-edge problem).
A couple things that people have found that are relevant to the exploration question in MBRL:
- model accuracy is proportional to data coverage,
- sampling-based controllers work by averaging out to the correct sequence,
- sampling-based controllers also generate totally new actions by straight up messing up.
A case study
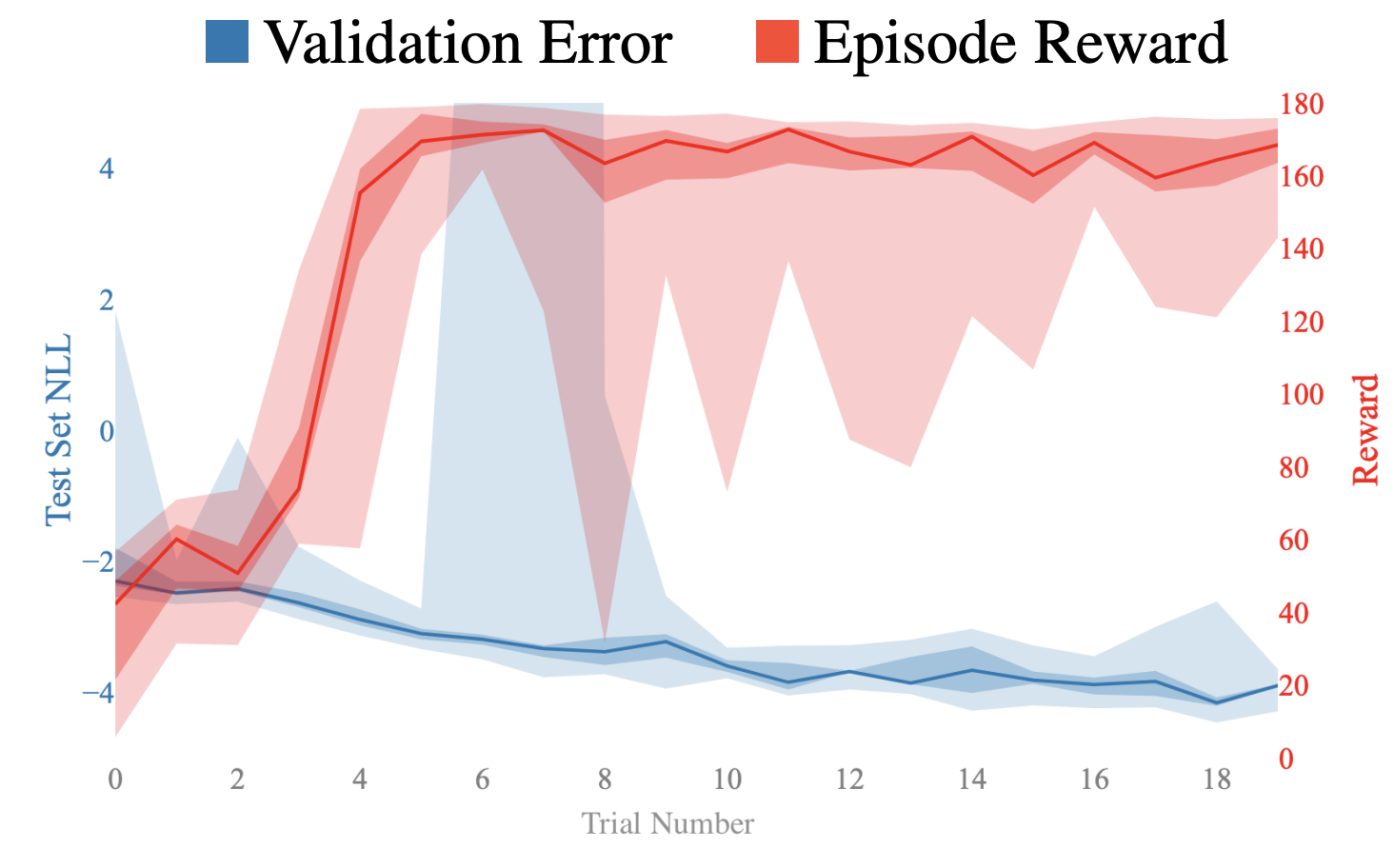
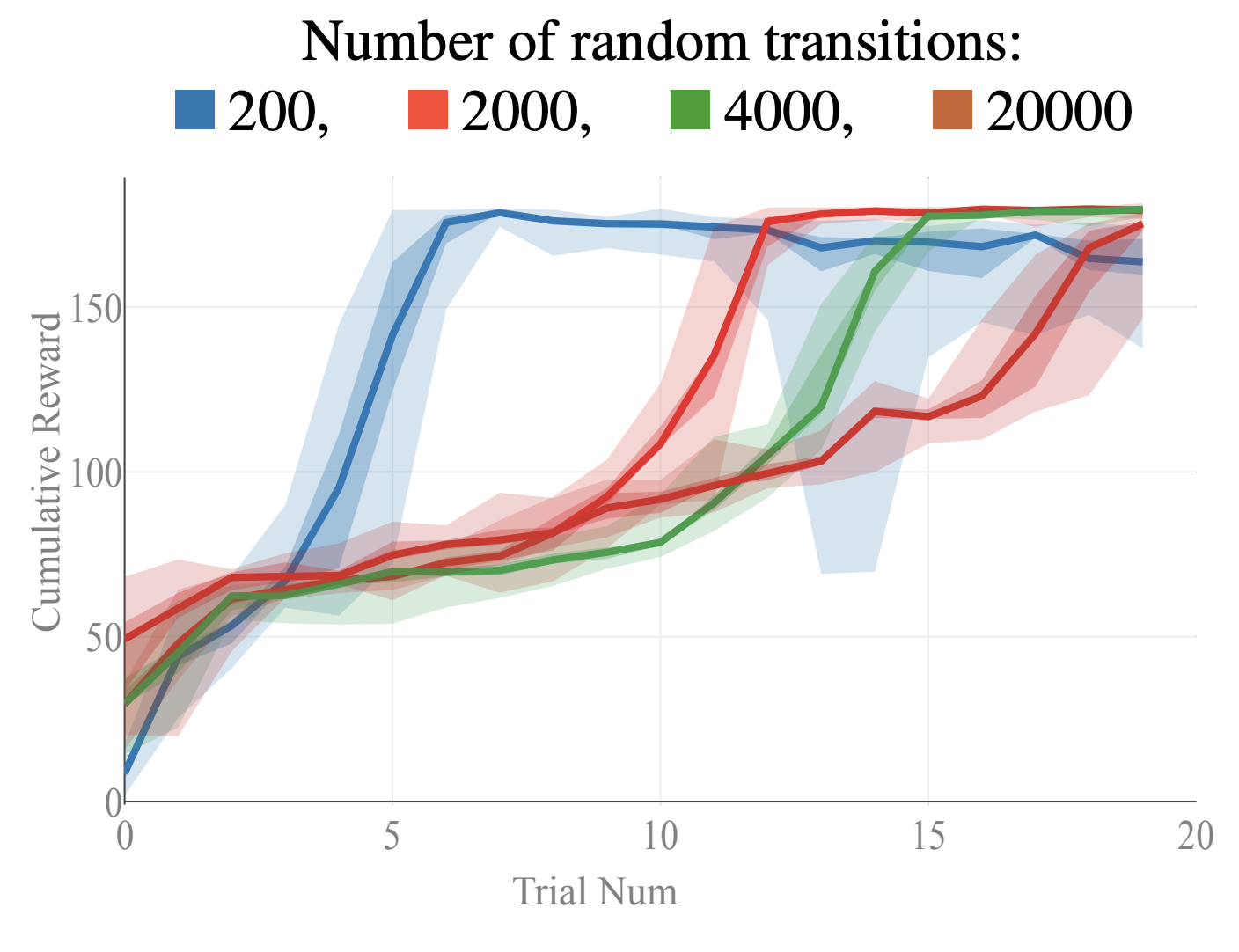
These lessons are from the appendix of my paper Objective Mismatch in Model-based Reinforcement Learning. Here I show had data distributions can show us the complexity of the exploration problem in MBRL. Essentially we use the PETS optimizer to see how a given dynamics model can solve nearby tasks. By doing this, we see what data was explored in the process of solving the task. Below we also look at how the model "accuracy" improves over time (even though it is separate from task performance) and how augmenting a dataset with more random samples can stall the learning process.
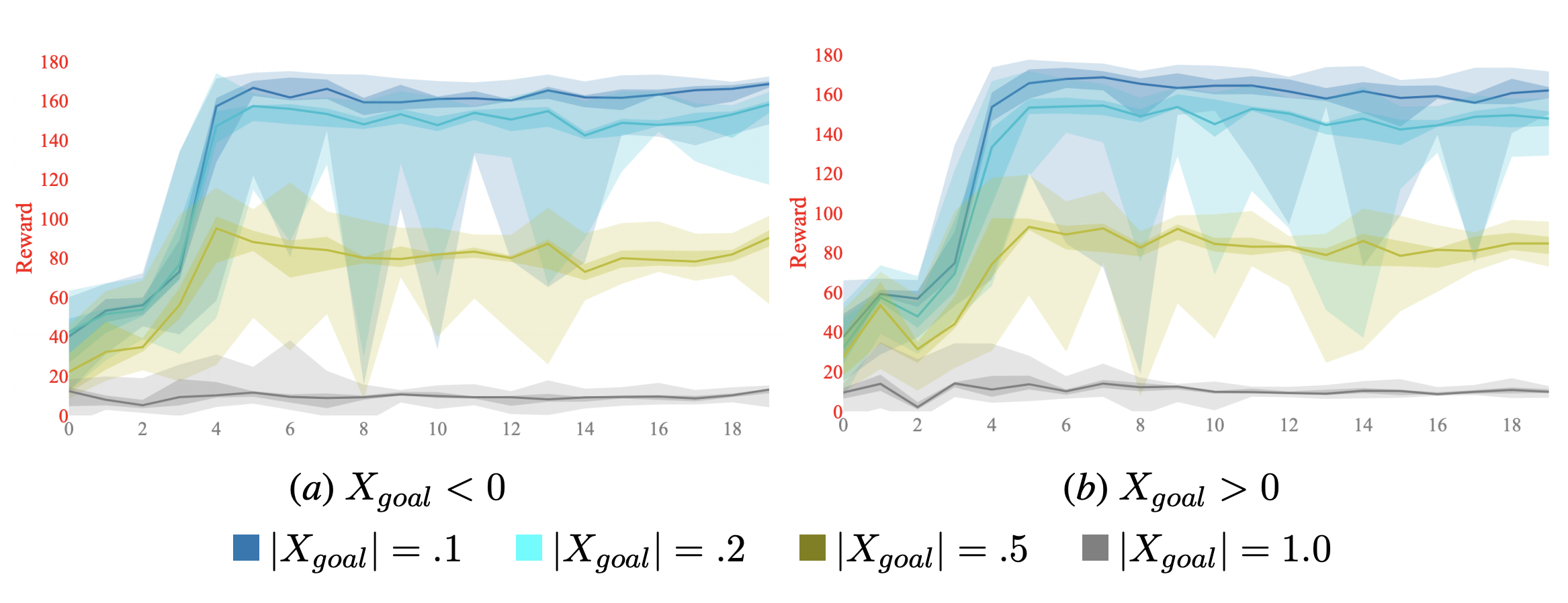
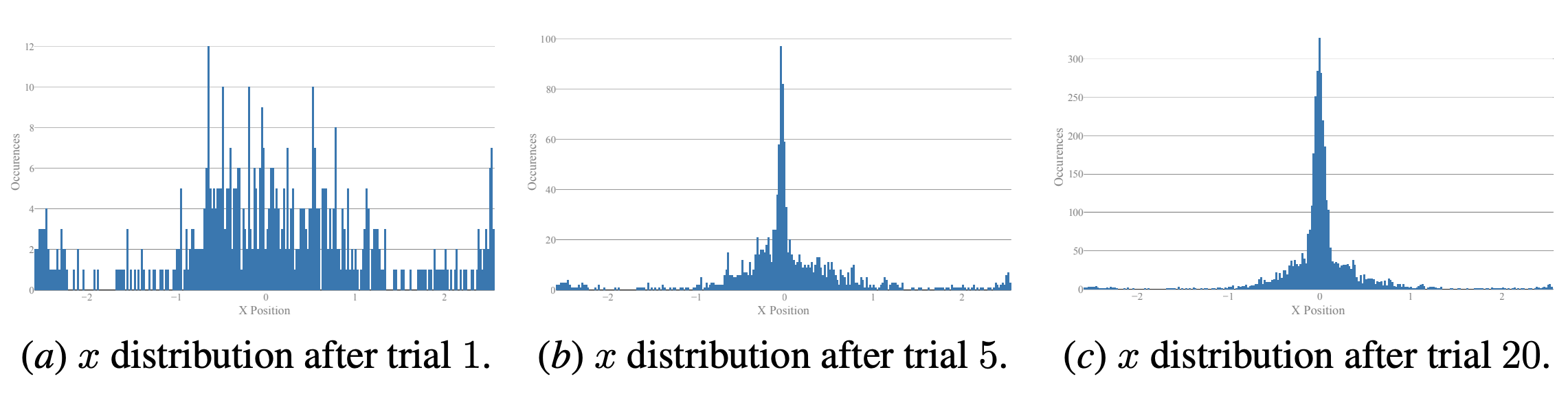
Some tools for exploration in MBRL
Here are some thoughts for how exploration could be used as a tool in model-based reinforcement learning:
- Variance-based control: If a model has a variance estimate in its forward pass (like many probabilistic ensembles that are used now), then it can incorporate that at control time. It can try to keep a certain amount of uncertainty to the chosen actions are somewhat based on known dynamics. I know a couple people trying to do this, but it hasn’t worked well yet, so maybe the total randomness of sample-based control is the reason MBRL works in that regime.
- Hybrid training and testing times (this lends itself nicely to real robots): Have an exploration metric you only use at training time. This is done in some model-free RL, but what is the exploration metric when you are searching for state-action data rather than just looking at an action distribution.
- Structured exploration (like entropy-based methods, SAC): I think there is a future here in model-based RL, but it may come after some more improvements are made to the model and to the optimizer, as then the system will be a little more probe-able (right now MBRL systems are confusing and opaque in parts).
Exploration in big, under-designed systems
If big companies deploy learning based systems, especially with RL, the method for exploration will be crucial. The action space may be so broad (amount of content) that no human designer can really understand it. Doubly, truly random actions (as done in epsilon-greedy exploration) may make no sense at all.
I think we may see this exploitation exploration on things like social media when they add RL (because users will complain if the company says we are showing you truly random content to build our dataset). I’m just reluctant because no one has studied it enough to know how it works.
Characterizing exploration in MBRL and other iterative data-building systems is worth studying a bit more.